Many modern machine learning algorithms have a large number of hyperparameters. To effectively use these algorithms, we need to pick good hyperparameter values. In this article, we talk about Bayesian Optimization, a suite of techniques often used to tune hyperparameters. More generally, Bayesian Optimization can be used to optimize any black-box function.
Mining Gold!
Let us start with the example of gold mining. Our goal is to mine for gold in an unknown land
Let us suppose that the gold distribution looks something like the function below. It is bi-modal, with a maximum value around . For now, let us not worry about the X-axis or the Y-axis units.

Initially, we have no idea about the gold distribution. We can learn the gold distribution by drilling at different locations. However, this drilling is costly. Thus, we want to minimize the number of drillings required while still finding the location of maximum gold quickly.
We now discuss two common objectives for the gold mining problem.
-
Problem 1: Best Estimate of Gold Distribution (Active Learning)
In this problem, we want to accurately estimate the gold distribution on the new land. We can not drill at every location due to the prohibitive cost. Instead, we should drill at locations providing high information about the gold distribution. This problem is akin to Active Learning. -
Problem 2: Location of Maximum Gold (Bayesian Optimization)
In this problem, we want to find the location of the maximum gold content. We, again, can not drill at every location. Instead, we should drill at locations showing high promise about the gold content. This problem is akin to Bayesian Optimization.
We will soon see how these two problems are related, but not the same.
Active Learning
For many machine learning problems, unlabeled data is readily available. However, labeling (or querying) is often expensive. As an example, for a speech-to-text task, the annotation requires expert(s) to label words and sentences manually. Similarly, in our gold mining problem, drilling (akin to labeling) is expensive.
Active learning minimizes labeling costs while maximizing modeling accuracy. While there are various methods in active learning literature, we look at uncertainty reduction. This method proposes labeling the point whose model uncertainty is the highest. Often, the variance acts as a measure of uncertainty.
Since we only know the true value of our function at a few points, we need a surrogate model for the values our function takes elsewhere. This surrogate should be flexible enough to model the true function. Using a Gaussian Process (GP) is a common choice, both because of its flexibility and its ability to give us uncertainty estimates
Please find this amazing video from Javier González on Gaussian Processes.
Our surrogate model starts with a prior of — in the case of gold, we pick a prior assuming that it’s smoothly distributed
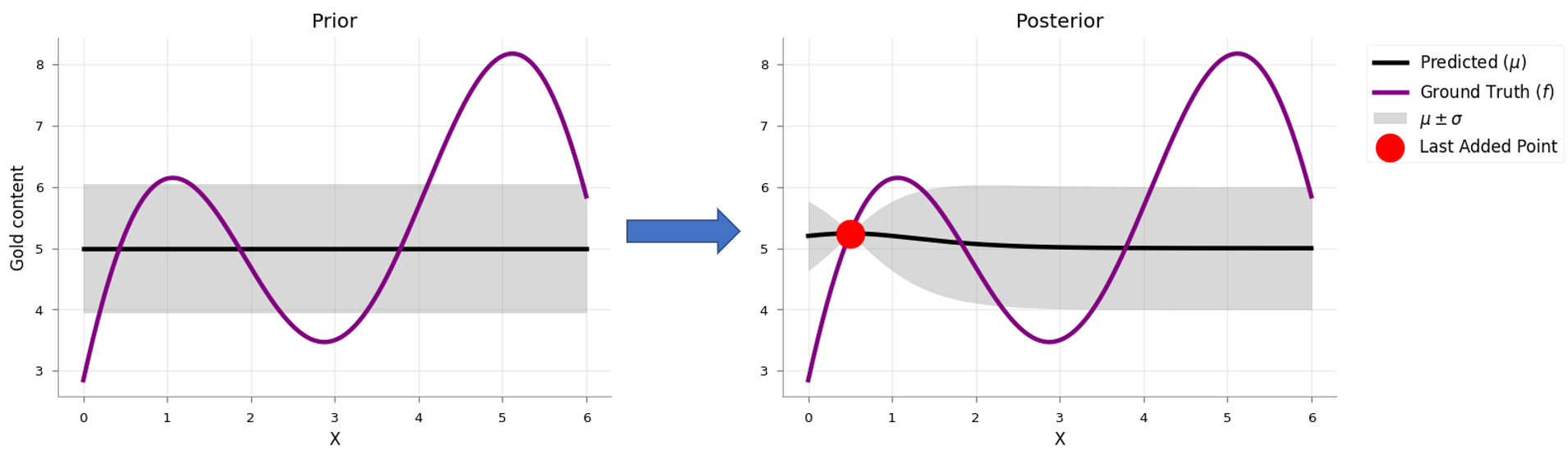
In the above example, we started with uniform uncertainty. But after our first update, the posterior is certain near and uncertain away from it. We could just keep adding more training points and obtain a more certain estimate of .
However, we want to minimize the number of evaluations. Thus, we should choose the next query point “smartly” using active learning. Although there are many ways to pick smart points, we will be picking the most uncertain one.
This gives us the following procedure for Active Learning:
- Choose and add the point with the highest uncertainty to the training set (by querying/labeling that point)
- Train on the new training set
- Go to #1 till convergence or budget elapsed
Let us now visualize this process and see how our posterior changes at every iteration (after each drilling).

The visualization shows that one can estimate the true distribution in a few iterations. Furthermore, the most uncertain positions are often the farthest points from the current evaluation points. At every iteration, active learning explores the domain to make the estimates better.
Bayesian Optimization
In the previous section, we picked points in order to determine an accurate model of the gold content. But what if our goal is simply to find the location of maximum gold content? Of course, we could do active learning to estimate the true function accurately and then find its maximum. But that seems pretty wasteful — why should we use evaluations improving our estimates of regions where the function expects low gold content when we only care about the maximum?
This is the core question in Bayesian Optimization: “Based on what we know so far, which point should we evaluate next?” Remember that evaluating each point is expensive, so we want to pick carefully! In the active learning case, we picked the most uncertain point, exploring the function. But in Bayesian Optimization, we need to balance exploring uncertain regions, which might unexpectedly have high gold content, against focusing on regions we already know have higher gold content (a kind of exploitation).
We make this decision with something called an acquisition function. Acquisition functions are heuristics for how desirable it is to evaluate a point, based on our present model
This brings us to how Bayesian Optimization works. At every step, we determine what the best point to evaluate next is according to the acquisition function by optimizing it. We then update our model and repeat this process to determine the next point to evaluate.
You may be wondering what’s “Bayesian” about Bayesian Optimization if we’re just optimizing these acquisition functions. Well, at every step we maintain a model describing our estimates and uncertainty at each point, which we update according to Bayes’ rule
Formalizing Bayesian Optimization
Let us now formally introduce Bayesian Optimization. Our goal is to find the location () corresponding to the global maximum (or minimum) of a function . We present the general constraints in Bayesian Optimization and contrast them with the constraints in our gold mining exampleGeneral Constraints |
Constraints in Gold Mining example |
|---|---|
| ’s feasible set is simple, e.g., box constraints. | Our domain in the gold mining problem is a single-dimensional box constraint: . |
| is continuous but lacks special structure, e.g., concavity, that would make it easy to optimize. | Our true function is neither a convex nor a concave function, resulting in local optimums. |
| is derivative-free: evaluations do not give gradient information. | Our evaluation (by drilling) of the amount of gold content at a location did not give us any gradient information. |
| is expensive to evaluate: the number of times we can evaluate it is severely limited. | Drilling is costly. |
| may be noisy. If noise is present, we will assume it is independent and normally distributed, with common but unknown variance. | We assume noiseless measurements in our modeling (though, it is easy to incorporate normally distributed noise for GP regression). |
To solve this problem, we will follow the following algorithm:
- We first choose a surrogate model for modeling the true function and define its prior.
- Given the set of observations (function evaluations), use Bayes rule to obtain the posterior.
- Use an acquisition function , which is a function of the posterior, to decide the next sample point .
- Add newly sampled data to the set of observations and goto step #2 till convergence or budget elapses.
Acquisition Functions
Acquisition functions are crucial to Bayesian Optimization, and there are a wide variety of options
Probability of Improvement (PI)
This acquisition function chooses the next query point as the one which has the highest probability of improvement over the current max . Mathematically, we write the selection of next point as follows,
where,
- indicates probability
- is a small positive number
- And, where is the location queried at time step.
Looking closely, we are just finding the upper-tail probability (or the CDF) of the surrogate posterior. Moreover, if we are using a GP as a surrogate the expression above converts to,
where,
- indicates the CDF
The visualization below shows the calculation of . The orange line represents the current max (plus an ) or . The violet region shows the probability density at each point. The grey regions show the probability density below the current max. The “area” of the violet region at each point represents the “probability of improvement over current maximum”. The next point to evaluate via the PI criteria (shown in dashed blue line) is .
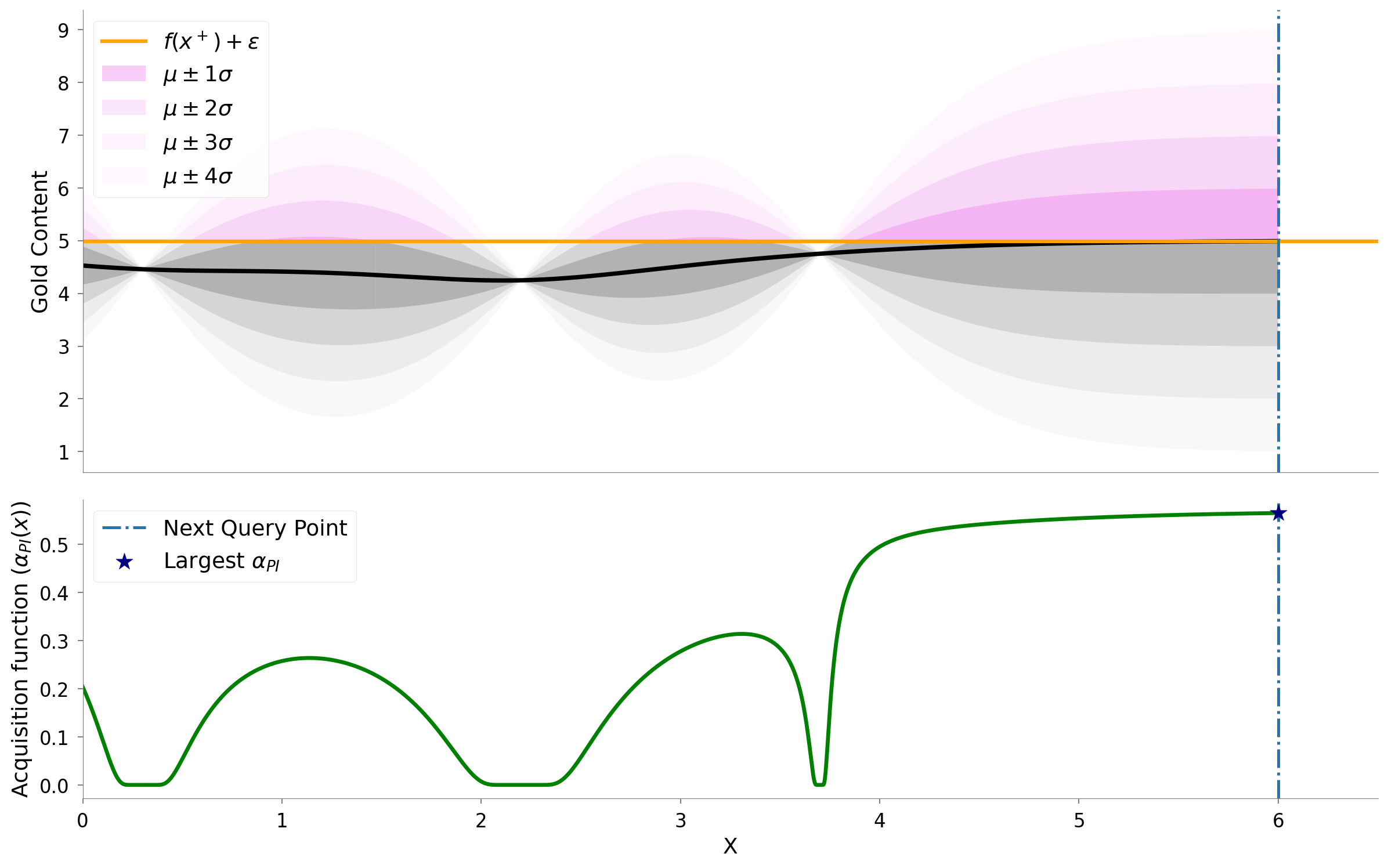
Intuition behind in PI
PI uses to strike a balance between exploration and exploitation. Increasing results in querying locations with a larger as their probability density is spread.
Let us now see the PI acquisition function in action. We start with .
.png)
Looking at the graph above, we see that we reach the global maxima in a few iterations
.png)
The visualization above shows that increasing to 0.3, enables us to explore more. However, it seems that we are exploring more than required.
What happens if we increase a bit more?
.png)
We see that we made things worse! Our model now uses , and we are unable to exploit when we land near the global maximum. Moreover, with high exploration, the setting becomes similar to active learning.
Our quick experiments above help us conclude that controls the degree of exploration in the PI acquisition function.
Expected Improvement (EI)
Probability of improvement only looked at how likely is an improvement, but, did not consider how much we can improve. The next criterion, called Expected Improvement (EI), does exactly that
In this acquisition function, query point, , is selected according to the following equation.
Where, is the actual ground truth function, is the posterior mean of the surrogate at timestep, is the training data and is the actual position where takes the maximum value.
In essence, we are trying to select the point that minimizes the distance to the objective evaluated at the maximum. Unfortunately, we do not know the ground truth function, . Mockus
where is the maximum value that has been encountered so far. This equation for GP surrogate is an analytical expression shown below.
where indicates CDF and indicates pdf.
From the above expression, we can see that Expected Improvement will be high when: i) the expected value of is high, or, ii) when the uncertainty around a point is high.
Like the PI acquisition function, we can moderate the amount of exploration of the EI acquisition function by modifying .
.png)
For we come close to the global maxima in a few iterations.
We now increase to explore more.
.png)
As we expected, increasing the value to makes the acquisition function explore more. Compared to the earlier evaluations, we see less exploitation. We see that it evaluates only two points near the global maxima.
Let us increase even more.
.png)
Is this better than before? It turns out a yes and a no; we explored too much at and quickly reached near the global maxima. But unfortunately, we did not exploit to get more gains near the global maxima.
PI vs Ei
We have seen two closely related methods, The Probability of Improvement and the Expected Improvement.

The scatter plot above shows the policies’ acquisition functions evaluated on different points
Thompson Sampling
Another common acquisition function is Thompson Sampling
Below we have an image showing three sampled functions from the learned surrogate posterior for our gold mining problem. The training data constituted the point and the corresponding functional value.

We can understand the intuition behind Thompson sampling by two observations:
-
Locations with high uncertainty () will show a large variance in the functional values sampled from the surrogate posterior. Thus, there is a non-trivial probability that a sample can take high value in a highly uncertain region. Optimizing such samples can aid exploration.
As an example, the three samples (sample #1, #2, #3) show a high variance close to . Optimizing sample 3 will aid in exploration by evaluating .
-
The sampled functions must pass through the current max value, as there is no uncertainty at the evaluated locations. Thus, optimizing samples from the surrogate posterior will ensure exploiting behavior.
As an example of this behavior, we see that all the sampled functions above pass through the current max at . If were close to the global maxima, then we would be able to exploit and choose a better maximum.
.png)
The visualization above uses Thompson sampling for optimization. Again, we can reach the global optimum in relatively few iterations.
Random
We have been using intelligent acquisition functions until now. We can create a random acquisition function by sampling randomly.
.png)
The visualization above shows that the performance of the random acquisition function is not that bad! However, if our optimization was more complex (more dimensions), then the random acquisition might perform poorly.
Summary of Acquisition Functions
Let us now summarize the core ideas associated with acquisition functions: i) they are heuristics for evaluating the utility of a point; ii) they are a function of the surrogate posterior; iii) they combine exploration and exploitation; and iv) they are inexpensive to evaluate.
Other Acquisition Functions
We have seen various acquisition functions until now. One trivial way to come up with acquisition functions is to have a explore/exploit combination.
Upper Confidence Bound (UCB)
One such trivial acquisition function that combines the exploration/exploitation tradeoff is a linear combination of the mean and uncertainty of our surrogate model. The model mean signifies exploitation (of our model’s knowledge) and model uncertainty signifies exploration (due to our model’s lack of observations).
The intuition behind the UCB acquisition function is weighing of the importance between the surrogate’s mean vs. the surrogate’s uncertainty. The above is the hyperparameter that can control the preference between exploitation or exploration.
We can further form acquisition functions by combining the existing acquisition functions though the physical interpretability of such combinations might not be so straightforward. One reason we might want to combine two methods is to overcome the limitations of the individual methods.
Probability of Improvement + Expected Improvement (EI-PI)
One such combination can be a linear combination of PI and EI. We know PI focuses on the probability of improvement, whereas EI focuses on the expected improvement. Such a combination could help in having a tradeoff between the two based on the value of .
Gaussian Process Upper Confidence Bound (GP-UCB)
Before talking about GP-UCB, let us quickly talk about regret. Imagine if the maximum gold was units, and our optimization instead samples a location containing units, then our regret is
. If we accumulate the regret over iterations, we get what is called cumulative regret.
GP-UCB’s
Where is the timestep.
Srinivas et. al.
Comparison
We now compare the performance of different acquisition functions on the gold mining problem

The random strategy is initially comparable to or better than other acquisition functions
Hyperparameter Tuning
Before we talk about Bayesian optimization for hyperparameter tuning
In Ridge regression, the weight matrix is the parameter, and the regularization coefficient is the hyperparameter.
If we solve the above regression problem via gradient descent optimization, we further introduce another optimization parameter, the learning rate .
The most common use case of Bayesian Optimization is hyperparameter tuning: finding the best performing hyperparameters on machine learning models.
When training a model is not expensive and time-consuming, we can do a grid search to find the optimum hyperparameters. However, grid search is not feasible if function evaluations are costly, as in the case of a large neural network that takes days to train. Further, grid search scales poorly in terms of the number of hyperparameters.
We turn to Bayesian Optimization to counter the expensive nature of evaluating our black-box function (accuracy).
Example 1 — Support Vector Machine (SVM)
In this example, we use an SVM to classify on sklearn’s moons dataset and use Bayesian Optimization to optimize SVM hyperparameters.
-
— modifies the behavior of the SVM’s kernel. Intuitively it is a measure of the influence of a single training example
StackOverflow answer for intuition behind the hyperparameters. . - — modifies the slackness of the classification, the higher the is, the more sensitive is SVM towards the noise.
Let us have a look at the dataset now, which has two classes and two features.

Let us apply Bayesian Optimization to learn the best hyperparameters for this classification task
.png)
Above we see a slider showing the work of the Probability of Improvement acquisition function in finding the best hyperparameters.
.png)
Above we see a slider showing the work of the Expected Improvement acquisition function in finding the best hyperparameters.
Comparison
Below is a plot that compares the different acquisition functions. We ran the random acquisition function several times to average out its results.

All our acquisition beat the random acquisition function after seven iterations. We see the random method seemed to perform much better initially, but it could not reach the global optimum, whereas Bayesian Optimization was able to get fairly close. The initial subpar performance of Bayesian Optimization can be attributed to the initial exploration.
Other Examples
Example 2 — Random Forest
Using Bayesian Optimization in a Random Forest Classifier.
We will continue now to train a Random Forest on the moons dataset we had used previously to learn the Support Vector Machine model. The primary hyperparameters of Random Forests we would like to optimize our accuracy are the number of Decision Trees we would like to have, the maximum depth for each of those decision trees.
The parameters of the Random Forest are the individual trained Decision Trees models.
We will be again using Gaussian Processes with Matern kernel to estimate and predict the accuracy function over the two hyperparameters.
.png)
Above is a typical Bayesian Optimization run with the Probability of Improvement acquisition function.
.png)
Above we see a run showing the work of the Expected Improvement acquisition function in optimizing the hyperparameters.
.png)
Now using the Gaussian Processes Upper Confidence Bound acquisition function in optimizing the hyperparameters.
.png)
Let us now use the Random acquisition function.

The optimization strategies seemed to struggle in this example. This can be attributed to the non-smooth ground truth. This shows that the effectiveness of Bayesian Optimization depends on the surrogate’s efficiency to model the actual black-box function. It is interesting to notice that the Bayesian Optimization framework still beats the random strategy using various acquisition functions.
Example 3 — Neural Networks
Let us take this example to get an idea of how to apply Bayesian Optimization to train neural networks. Here we will be using scikit-optim, which also provides us support for optimizing function with a search space of categorical, integral, and real variables. We will not be plotting the ground truth here, as it is extremely costly to do so. Below are some code snippets that show the ease of using Bayesian Optimization packages for hyperparameter tuning.
The code initially declares a search space for the optimization problem. We limit the search space to be the following:
-
batch_size — This hyperparameter sets the number of training examples to combine to find the gradients for a single step in gradient descent.
Our search space for the possible batch sizes consists of integer values s.t. batch_size = . -
learning rate — This hyperparameter sets the stepsize with which we will perform gradient descent in the neural network.
We will be searching over all the real numbers in the range . - activation — We will have one categorical variable, i.e. the activation to apply to our neural network layers. This variable can take on values in the set .
Now import gp-minimizescikit-optim.scikit-optim to perform the optimization. Below we show calling the optimizer using Expected Improvement, but of course we can select from a number of other acquisition functions.

In the graph above the y-axis denotes the best accuracy till then, and the x-axis denotes the evaluation number.
Looking at the above example, we can see that incorporating Bayesian Optimization is not difficult and can save a lot of time. Optimizing to get an accuracy of nearly one in around seven iterations is impressive!scikit-optim.
Let us get the numbers into perspective. If we had run this optimization using a grid search, it would have taken around iterations. Whereas Bayesian Optimization only took seven iterations. Each iteration took around fifteen minutes; this sets the time required for the grid search to complete around seventeen hours!
Conclusion and Summary
In this article, we looked at Bayesian Optimization for optimizing a black-box function. Bayesian Optimization is well suited when the function evaluations are expensive, making grid or exhaustive search impractical. We looked at the key components of Bayesian Optimization. First, we looked at the notion of using a surrogate function (with a prior over the space of objective functions) to model our black-box function. Next, we looked at the “Bayes” in Bayesian Optimization — the function evaluations are used as data to obtain the surrogate posterior. We look at acquisition functions, which are functions of the surrogate posterior and are optimized sequentially. This new sequential optimization is in-expensive and thus of utility of us. We also looked at a few acquisition functions and showed how these different functions balance exploration and exploitation. Finally, we looked at some practical examples of Bayesian Optimization for optimizing hyper-parameters for machine learning models.
We hope you had a good time reading the article and hope you are ready to exploit the power of Bayesian Optimization. In case you wish to explore more, please read the Further Reading section below. We also provide our repository to reproduce the entire article.